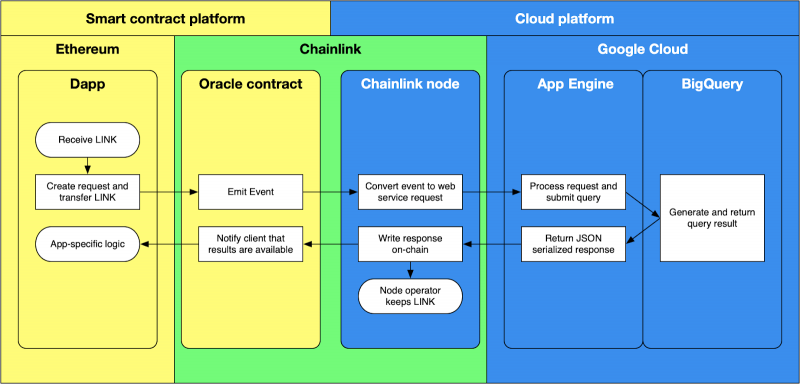
ГИБРИД & MULTI-ОБЛАЧНАЯ
Anthos Управление конфигурацией: GA
ГИБРИД & MULTI-ОБЛАЧНАЯ
Anthos Управление конфигурацией: GA
Управление конфигурацией и применять политики через ваши кластеры — являются ли они на территории или в облаке. Установите декларативную конфигурацию на основе ролей контроля доступа, квоты ресурсов и пространства имен — все из одного места.
Документация |
Блог
COMPUTE
Kubernetes двигателя — Intranode Видимость: бета
Эта особенность делает весь ваш сетевой трафик видимой в сеть опорных точек. Вы можете увидеть журналы потока для всего трафика между стручками, включая трафик между стручками на одном узле. И вы можете создать правила брандмауэра, которые применяются ко всему трафику между стручками.
Документация
Compute Engine — резервирование зональных ресурсов: бета
Резерв VM экземпляры в определенной зоне, чтобы убедиться, что они доступны для будущего роста спроса, например, плановых или внеплановых шипы, большие миграции, резервного копирования и аварийного восстановления, или запланированного роста. Вы можете создать или отменить заказ в любое время, без каких-либо обязательств.
Документация
API ПЛАТФОРМЫ & ECOSYSTEMS
Apigee Portal Разработчик — управление аудиторией и разработчик команды: бета
Эта версия позволяет пользователям портала разделить ответственность за приложение с другими пользователями портала, а также сегмент лиц, для того, чтобы контролировать доступ к контенту.
Документация |
Блог
AI & МАШИНА ОБУЧЕНИЯ
AI Платформа: Notebooks бета
Это управляемый сервис ноутбука предприятия позволяет получить проекты и работает в течение нескольких минут. В один клик вы можете создать экземпляры в JupyterLab, которые приходят предварительно установлены с последними научными данными и обучения машины рамок. Услуга доступна через платформу AI в Google Cloud Platform Console.
Документация
Разработка мобильных APP
IDENTITY & SECURITY
GKE Песочница: бета
Получить дополнительную безопасность для контейнеров Kubernetes двигателя — без дополнительной сложности. Это управляемый сервис, основанный на gVisor проекта с открытым исходным кодом, является решением контейнеров изоляции, что обеспечивает второй уровень защиты между вашей контейнерной нагрузкой на Kubernetes Engine.
Страница продукта |
Блог
Anthos
Anthos: GA
Эта программная открытая платформа позволяет просто и безопасно запускать ваше приложение — без изменений — локально или в облаке. Гибридная функциональность Anthos доступна на облачной платформе Google с Kubernetes Engine и в вашем центре обработки данных с GKE On-Prem. Скоро: управляйте своими рабочими нагрузками в сторонних облаках по вашему выбору.
Документация |
Блог
GCP Marketplace — приложения Kubernetes Интеграция Anthos: GA
Благодаря этому запуску большинство приложений Kubernetes, принадлежащих сторонним производителям, и часть приложений сторонних производителей на GCP Marketplace теперь совместимы с кластерами с поддержкой Istio, могут быть развернуты в кластерах GKE On-Prem и GCP и могут экспортироваться. Метрики Прометея.
GCP Marketplace
БАЗА ДАННЫХ
Облачный SQL для Microsoft SQL Server: альфа
С помощью этой службы вы можете перенести существующие рабочие нагрузки Microsoft SQL Server в GCP и запустить их в полностью управляемой службе базы данных. Вы можете легко настроить, поддерживать, управлять и администрировать ваши реляционные базы данных PostgreSQL, MySQL и SQL Server в облаке.
Страница продукта |
Блог
Облачный SQL для PostgreSQL — версия 11: бета
Облачный SQL для PostgreSQL стал одной из самых быстрорастущих баз данных в GCP в прошлом году. Эта последняя версия включает полезные новые функции, такие как улучшения разбиения, хранимые процедуры и больше параллелизма.
Документация |
Блог
AI & MACHINE ОБУЧЕНИЕ
Облачный ТПУ v3: GA
Облачные TPU от Google — это более быстрый и экономически эффективный способ решения больших задач машинного обучения и новейших моделей распознавания изображений, языковой обработки и многого другого. Теперь доступно последнее поколение Cloud TPU v3.
Блог
Таблицы AutoML: бета
Таблицы AutoML позволяют всей вашей команде автоматически создавать и развертывать современные модели машинного обучения на структурированных данных с огромным увеличением скорости и масштаба.
Документация |
Блог
AutoML Vision Edge: бета
Создание и развертывание быстрых, высокоточных моделей для классификации изображений на периферийных устройствах и запуска действий в реальном времени на основе локальных данных. AutoML Vision Edge поддерживает множество периферийных устройств, где ресурсы ограничены, а низкая задержка имеет решающее значение.
Документация |
Блог
Обнаружение объектов AutoML Vision: бета
В дополнение к классификации изображений AutoML Vision также может обнаруживать несколько объектов и предоставлять информацию о том, где каждый объект находится в изображении.
Документация |
Блог
AutoML Natural Language — выборочная сущность и анализ настроений: бета
В этом выпуске добавлена поддержка извлечения пользовательских объектов для автоматической идентификации и маркировки доменных ключевых слов и фраз в документах, а также поддержка пользовательского анализа настроений, настроенного на ваши собственные доменные оценки настроений, чтобы помочь понять общее отношение, выраженное в блоке текста.
Документация по извлечению сущностей |
Документация Анализ настроений |
Блог
Рекомендации AI: ограниченная бета
Рекомендации AI позволяет ритейлерам предоставлять высоко персонализированные рекомендации по продукту в масштабе. Он использует новейшие архитектуры машинного обучения Google для динамической адаптации к поведению клиентов в реальном времени и изменениям таких переменных, как ассортимент, цены и предложения. Рекомендации AI — это полностью управляемый сервис, который может легко интегрировать ваши данные и предоставлять рекомендации любому клиенту.
Страница продукта |
Документация |
Блог
Поиск продукта Cloud Vision: GA
Cloud Vision Product Search позволяет розничным продавцам встраивать функциональность визуального поиска в свои мобильные приложения, позволяя покупателям делать фотографии или снимки экрана с товарами и получать список аналогичных товаров, предлагаемых продавцом.
Документация |
Блог
Cloud Natural Language API: GA
Этот запуск помогает вам идентифицировать обычные объекты чеков и счетов-фактур, такие как даты, адреса и номера телефонов, чтобы сэкономить время на ручных аннотациях и анализе. Он также включает в себя поддержку на японском языке для анализа сущностей и настроений и поддержку на русском языке для анализа сущностей.
Документация |
Блог
Cloud Translation API v3: бета
Эта последняя версия Cloud Translation API добавляет функцию глоссария, которая позволяет вам определять словарь для конкретной компании, который вы хотите переопределить общие результаты перевода. Он также позволяет выполнять пакетные переводы для поддержки больших объемов контента в одном запросе и дает возможность выбрать лучшую модель, соответствующую вашим потребностям в переводе, включая пользовательские модели.
Документация |
Блог
Служба маркировки данных платформы AI: бета
Служба маркировки данных позволяет вам пометить данные человеком, подготовив их к высококачественному набору данных для модели машинного обучения. Он поддерживает наиболее популярные варианты использования изображений, видео и текстовых аннотаций, включая классификацию, обнаружение объектов и извлечение объектов.
Документация
ИНФРАСТРУКТУРА
Новые регионы GCP — Сеул, Южная Корея и Солт-Лейк-Сити
В начале 2020 года появятся два новых дополнения к глобальной инфраструктуре Google Cloud: Сеул, Южная Корея и Солт-Лейк-Сити. Оба региона будут рассчитаны на высокую доступность с тремя зонами с самого начала и будут включать все ключевые продукты GCP.
Блог |
Документация
АНАЛИТИКА ДАННЫХ
Облачный поток данных — Streaming Engine: GA
Эта функция позволяет перемещать части конвейерного выполнения с рабочих виртуальных машин в серверную часть облачного потока данных. Это уменьшает потребление ресурсов ЦП и постоянного диска, обеспечивает более быстрое автоматическое масштабирование и улучшает поддержку. Streaming Engine теперь также доступен в двух дополнительных регионах GCP: европа-запад4 (Нидерланды) и азия-северо-восток1 (Токио).
Документация
Cloud Composer — обновления среды: бета
Теперь одним щелчком мыши вы можете легко обновить версию Airflow или Cloud Composer, которая работает в вашей среде.
Документация
Cloud Composer — частная IP-среда: бета
Теперь, когда вы включаете частный IP, Cloud Composer назначает только частные IP-адреса управляемым виртуальным машинам Kubernetes Engine и Cloud SQL в вашей среде, эффективно предотвращая входящий доступ к этим управляемым виртуальным машинам из общедоступного Интернета.
Документация
Cloud Pub / Sub — аутентифицированный push: бета
Теперь Cloud Pub / Sub может безопасно инициировать принудительные конечные точки, используя учетные записи служб и Cloud Identity and Access Management. Push-конечные точки могут проверять подлинность отправителя сообщения и целевого удостоверения, а службы GCP получателя могут использовать Cloud IAM для авторизации push-запросов.
Документация
Облачный поток данных — новые регионы: GA
Получите географическую надежность для инфраструктуры обработки данных — теперь с возможностью запуска заданий Cloud Dataflow в азиатско-северо-восточном регионе2 в Осаке, Япония. Cloud Toflow Streaming Engine и Cloud Dataflow Shuffle также доступны в Токио и Нидерландах с добавлением регионов Азия-Северо-Восток1 и Европа-Запад4.
Документация
BigQuery — кластеризация: GA
Разделите таблицы BigQuery по столбцам даты и метки времени, и с помощью этой новой возможности повторно кластеризуйте произвольные части таблицы. Первоначально кластеризация будет поддерживаться только на многораздельных таблицах, но будущие выпуски будут поддерживать кластеризацию и на нераздельных таблицах.
Документация
СЕТЕВАЯ
VPC Flow Logs — создание настраиваемых логов: бета
Теперь вы можете сбалансировать потребности в отображении трафика и затратах на хранение, предварительно указав интервал, с которым образцы пакетов собираются для данного подключения к виртуальной машине, и объединяются в одну запись журнала. Этот интервал может составлять от пяти секунд до 15 минут.
Документация |
Блог
Регистрация NAT в облаке: бета
Регистрация NAT в облаке позволяет регистрировать подключения и ошибки NAT. Если ведение журнала включено, все собранные журналы отправляются в Stackdriver по умолчанию. Журналы также содержат пропущенные исходящие пакеты в случае исчерпания порта.
Документация
БЕЗОПАСНОСТЬ
Политическая разведка: альфа
Представляем три новых инструмента ML, которые помогут администраторам управлять политиками IAM и снизить риски. Удалите нежелательный доступ к ресурсам GCP с помощью IAM Recommender. Понимать отклоненные запросы и изменять политики доступа с помощью средства устранения неполадок доступа. Используйте Validator для настройки управления и защиты.
Блог
Экранированный ВМ: GA
Экранированная виртуальная машина обеспечивает проверяемую целостность ваших экземпляров виртуальной машины Compute Engine, помогая защитить их от вредоносных программ или руткитов уровня загрузки или ядра. Используя функции защищенной виртуальной машины, такие как модуль виртуальной доверенной платформы, безопасная загрузка, измеренная загрузка и мониторинг целостности, вы можете обнаруживать низкоуровневые компромиссы платформ ваших виртуальных машин и снижать риск отфильтрованных данных.
Документация |
Блог
Предотвращение потери данных в облаке: бета
Новый интерфейс Cloud DLP обеспечивает быструю, масштабируемую классификацию для конфиденциальных данных, таких как номера кредитных карт или номеров социального страхования. Запускайте сканирование всего несколькими щелчками мыши — код не требуется, аппаратное обеспечение или виртуальные машины не требуются.
Страница продукта |
Блог
Access Context Manager — новые атрибуты: GA
Уровни доступа определяют различные атрибуты, которые используются для фильтрации запросов к определенным ресурсам. Мы добавили дополнительные атрибуты, которые вы можете использовать, включая геолокацию, одобренные администратором устройства, корпоративные устройства и доступ с проверкой Chrome.
Документация
Cloud Security Scanner: бета
Этот сканер веб-безопасности обнаруживает уязвимости, такие как межсайтовый скриптинг, неправильно настроенные заголовки безопасности, пароли в виде открытого текста и устаревшие библиотеки в ваших приложениях GCP. Он обычно доступен для App Engine и теперь доступен в бета-версии для Kubernetes Engine и Compute Engine.
Документация |
Блог
Идентификационная платформа: GA
Ранее известная как облачная идентификация для клиентов и партнеров, Identity Platform упрощает идентификацию клиентов и управление доступом и помогает вам уверенно масштабировать. Это также упрощает добавление IAM в ваши приложения и защиту учетных записей пользователей.
Документация |
Блог
COMPUTE
Compute Engine — принесите собственную лицензию: бета
Теперь вы можете принести свою собственную лицензию в Compute Engine, используя единоличные узлы и функцию перезапуска на месте. Узлы единственного арендатора предоставляют выделенное оборудование и позволяют увидеть основные характеристики вашего компьютера, чтобы обеспечить соответствие требованиям лицензии и требования к отчетности.
Документация |
Блог
Графические процессоры NVIDIA T4 на GCP: GA
Графические процессоры NVIDIA T4, которые в настоящее время доступны в восьми регионах мира, ускоряют различные облачные нагрузки, включая высокопроизводительные вычисления, обучение машинному обучению и выводу, анализ данных и графику.
Страница продукта |
Блог
Cloud Run: бета
Получите простой опыт развертывания и запуска служб без сохранения состояния в вашем кластере, включая автоматическое масштабирование на основе HTTP-запросов, масштабирование до нуля, автоматическое сетевое взаимодействие и интеграцию со Stackdriver. Запускайте свои безсерверные рабочие нагрузки в любом месте с помощью Google Cloud или Kubernetes Engine.
Документация |
Блог
МЕСТО ХРАНЕНИЯ
Облачное хранилище файлов: GA
Создайте полностью управляемые файловые серверы NFS на GCP для использования с приложениями, работающими на виртуальных машинах Compute Engine или кластерах Kubernetes Engine. Облачное хранилище файлов теперь предлагает SLA, а экземпляры премиум-класса теперь обеспечивают повышенную производительность чтения — до 1,2 ГБ / с и 60 000 операций ввода-вывода в секунду.
Документация |
Блог
Только политика хранилища облачных хранилищ: бета
Только Bucket Policy обеспечивает единообразное и непротиворечивое разрешение для всех объектов в пределах корзины путем настройки конфигурации IAM на уровне сегмента. Это упрощает разрешение, так как отдельные списки контроля доступа на уровне объектов отключены, и только разрешения IAM уровня сегмента разрешают доступ к блоку и его объектам.
Документация |
Блог
УПРАВЛЕНИЕ API
API Cloud Healthcare: бета
Теперь в GCP есть управляемое решение для хранения, обработки и де-идентификации медицинских данных, связывающее существующие системы ухода и приложения, размещенные в Google Cloud. API помогает организациям здравоохранения управлять отраслевыми данными, такими как EHR и визуализация, и лучше понимать данные с помощью аналитики и ML в реальном времени в масштабе.
Документация |
Блог
Гибрид апигея: бета
Этот новый вариант развертывания позволяет разместить среду выполнения в своем центре обработки данных или в общедоступном облаке по вашему выбору. Получите единственное, полнофункциональное решение для управления API во всех ваших средах с глобальным масштабом, гибкостью и согласованностью.
Документация |
Блог
ИНСТРУМЕНТЫ РАЗРАБОТЧИКА
Облачные задачи: GA
Этот полностью управляемый сервис позволяет вам управлять выполнением, распределением и доставкой распределенных задач. Облачные задачи обеспечивают надежную разгрузку задач, слабую связь между службами и повышенную надежность системы с настройкой скорости и пределами повторных попыток. Используйте облачные задачи для асинхронного выполнения работы, чтобы уменьшить задержку запросов, развязать и масштабировать микросервисы, управлять потреблением ресурсов и обрабатывать инциденты, не отбрасывая запросы.
Страница продукта
Облачный планировщик: GA
Cloud Scheduler — это полностью управляемый планировщик заданий корпоративного уровня. Это позволяет планировать практически любую работу, включая пакетную обработку, работу с большими данными, операции с облачной инфраструктурой и многое другое. Вы можете автоматизировать все, включая повторные попытки в случае сбоя, чтобы уменьшить ручной труд и вмешательство. Cloud Scheduler даже действует как единое стекло, позволяя вам управлять всеми задачами автоматизации из одного места.
Документация
ПОДДЕРЖКА GOOGLE CLOUD PLATFORM
Поддержка GCP для Firebase: GA
Этот запуск включает в себя обновленное руководство Службы технической поддержки GCP (TSS). Все службы Firebase теперь имеют право на TSS, за исключением приглашений Firebase, индексации приложений Firebase, динамических ссылок Firebase, Google Analytics для Firebase и базы данных реального времени Firebase.
Документация
Anthos
Приложения Kubernetes в Google Cloud Platform Marketplace: GA
Приложения Kubernetes — это готовые к работе контейнерные решения с готовыми шаблонами развертывания. Этот последний запуск выпускает 48 бета-тестовых коммерческих приложений Kubernetes в GCP Marketplace от бета-версии до GA.
Сайт |
Документация
БАЗА ДАННЫХ
Cloud Bigtable — мультирегиональная репликация: GA
Теперь вы можете настроить асинхронную репликацию между четырьмя кластерами в одном экземпляре, расположенном в любом подмножестве зон по всему миру. Это устраняет ограничение в одном и том же регионе для выбора местоположения кластера, предоставляя вам возможность сделать ваши данные доступными по всему региону или по всему миру.
Документация |
Блог
AI & MACHINE ОБУЧЕНИЕ
Документ Понимание AI: бета
Эта масштабируемая безсерверная платформа позволяет автоматически классифицировать, извлекать и обогащать данные в отсканированных или цифровых документах. Он превращает ваши документы в структурированные данные, помогая автоматизировать рабочие процессы обработки документов и разблокировать скрытые знания в вашей организации.
Страница продукта |
Блог
Контакт-центр AI: бета
Мы объединили лучшее из Google AI с популярным программным обеспечением контакт-центра, чтобы улучшить ваш опыт и повысить эффективность работы. Мы сотрудничаем с ведущими поставщиками услуг телефонии и системными интеграторами, поэтому вы можете легко включить Contact Center AI с вашими существующими решениями.
Страница продукта |
Блог
AI Hub: бета
AI Hub дополняет новую платформу AI, предлагая вам управляемые API машинного обучения, модули TensorFlow, ноутбуки, сквозные конвейеры ML и многое другое. Делитесь активами ML внутри своей организации, чтобы масштабировать влияние ресурсов ML и способствовать их повторному использованию и совместной работе.
Документация |
Блог |
Решение
Панель инструментов AI Platform: бета
Этот выпуск предлагает унифицированную целевую страницу для всех продуктов AI Platform, предоставляя управляемый сервис для ноутбуков и инструменты для маркировки данных. Он также помогает запускать Kubeflow Pipelines в GCP и перемещать локальный код приложения в GCP с минимальными изменениями.
Страница продукта |
Блог
AutoML Video Intelligence: бета
Создайте пользовательские модели, которые автоматически классифицируют видеоконтент с определенными вами метками. Теперь вы можете загружать свои собственные видеозаписи и пользовательские теги, чтобы обучать модели, которые соответствуют вашим потребностям бизнеса, например, для тегов и извлечения видео с пользовательскими атрибутами.
Документация |
Блог
АНАЛИТИКА ДАННЫХ
Облачный поток данных — гибкое планирование ресурсов: бета
FlexRS снижает затраты на пакетную обработку, используя передовые методы планирования, службу Cloud Dataflow Shuffle и комбинацию вытесняемых и обычных экземпляров виртуальных машин.
Документация |
Блог
Облачный поток данных Shuffle — новые регионы: GA
Эта функция, доступная только для пакетных конвейеров, позволяет экономить ресурсы, перемещая операцию перемешивания из экземпляров рабочих виртуальных машин в серверную часть облачного потока данных. В настоящее время он обычно доступен в регионах Азия-Северо-Восток1 (Токио) и Европа-Запад4 (Нидерланды).
Документация
BigQuery Географические информационные системы: GA
BigQuery GIS позволяет анализировать и визуализировать геопространственные данные в BigQuery, используя типы данных географии и стандартные функции географии SQL.
Документация |
Блог
BigQuery BI Engine: бета
С помощью этой полностью управляемой службы анализа в памяти вы можете в интерактивном режиме анализировать сложные наборы данных с помощью времени отклика до доли секунды и высокой степени параллелизма через Google Data Studio. В ближайшие месяцы BigQuery BI Engine будет интегрирован с подключенными электронными таблицами в Sheets и с инструментами бизнес-аналитики партнеров.
Документация |
Блог
Cloud Data Fusion: бета
Этот полностью управляемый сервис интеграции данных для предприятий позволяет легко создавать надежные, масштабируемые решения для интеграции данных для очистки, подготовки, смешивания, передачи и преобразования данных из разнородных источников — без необходимости бороться с инфраструктурой.
Документация |
Блог
BigQuery фиксированная цена: GA
Теперь мы предлагаем модель ценообразования с фиксированной ставкой для клиентов, которые предпочитают платить фиксированные ежемесячные расходы за запросы, а не переменную цену по запросу. Зарегистрируйтесь и приобретите специальные возможности обработки запросов, измеренные в слотах BigQuery. Минимальный размер теперь составляет 500 слотов по 10000 долларов в месяц.
Документация
СЕТЕВАЯ
Cloud Interconnect 100G: бета
Cloud Interconnect обеспечивает высокодоступные соединения с низкой задержкой, которые позволяют надежно передавать данные между локальной сетью и сетями VPC. С этим запуском вы можете теперь запрашивать 100G соединений, в дополнение к 10G.
Документация |
Блог
Директор по трафику: бета
Эта полностью управляемая плоскость управления трафиком для открытой сервисной сетки позволяет легко развертывать глобальную балансировку нагрузки между кластерами и экземплярами виртуальных машин в нескольких регионах, выполнять проверку работоспособности от прокси служб и настраивать сложные политики управления трафиком.
Документация |
Блог
Балансировка нагрузки в облаке — новые функции внутренней балансировки нагрузки TCP / UDP L4: бета
Новые функции включают в себя обнаружение служб на основе DNS (бета), все порты L4 ILB (GA) и группы аварийного переключения L4 ILB (бета).
Блог |
Документация
МИГРАЦИЯ
Служба передачи данных BigQuery: бета и альфа
Упростите миграцию в Google Cloud и значительно сократите время миграции с помощью BigQuery Data Transfer Service, который автоматизирует миграцию данных и схем в BigQuery из Teradata, а также загрузку данных из Amazon S3, которые сейчас находятся в стадии бета-тестирования. Автоматизированная миграция данных из Amazon Redshift теперь в альфа-версии.
Страница продукта
БЕЗОПАСНОСТЬ
Облачный Identity-Aware Proxy — контекстно-зависимый доступ: GA
Получите помощь в защите экземпляров виртуальных машин — и теперь как облачных, так и локальных веб-приложений — с контекстно-зависимым доступом, который позволяет принудительно применять доступ к приложениям и инфраструктуре на основе личности пользователя и контекста их запроса. Принять модель управления доступом на уровне приложения вместо того, чтобы полагаться на VPN на уровне сети.
Документация |
Блог
Разрешение на доступ: бета
Утвердите или отклоните запросы на доступ от сотрудников Google, работающих для поддержки вашего сервиса. Access Approval отправит вам электронное письмо или сообщение Cloud Pub / Sub с запросом на доступ, который затем можно будет одобрить с помощью консоли GCP или API Access Access.
Документация |
Блог
Командный центр облачной безопасности: GA
Получите доступ к этой платформе управления безопасностью и рисками для GCP, чтобы лучше понять вашу безопасность и поверхность атаки данных Обладая такими возможностями, как Security Health Analytics и Cloud Security Scanner, Cloud SCC помогает группам безопасности предотвращать, обнаруживать и реагировать на угрозы с единой стеклянной панели.
Документация |
Блог
Cloud SCC — обнаружение угрозы события: бета
Это новое средство безопасности сканирует журналы Stackdriver для обнаружения подозрительных действий, таких как вредоносные программы, крипто-майнинг и исходящие DDoS-атаки. Он помечает результаты для исправления и выявляет угрозы в Cloud SCC.
Блог
Android-телефон — встроенные ключи безопасности: бета
Одна из самых надежных средств защиты от фишинга — технология FIDO Security Key — теперь доступна в телефонах Android без дополнительной оплаты. Вам больше не нужно покупать фактический ключ, это означает, что эта технология безопасности теперь доступна любому, у кого есть телефон с Android.
Блог
COMPUTE
Compute Engine — регистрация выходов последовательного порта в Stackdriver: GA
Теперь вы можете настроить экземпляры виртуальной машины Compute Engine для автоматической отправки выходных данных последовательного порта в ведение журнала Stackdriver. Для экземпляров виртуальной машины, которые больше не работают, вы все равно сможете найти и просмотреть выходные данные последовательного порта, сохраненные в журнале Stackdriver.
Документация
Kubernetes Engine — управляемые сертификаты: бета
Управляемые сертификаты SSL упрощают процесс включения HTTPS-соединения. Они обновляются автоматически и отменяются при удалении прокси. Обладая управляемыми сертификатами, Cloud Load Balancing по умолчанию шифрует пользовательские соединения, исключая ручную работу.
Документация
Облачные функции — максимум экземпляров: бета
В этом выпуске вы можете ограничить степень масштабирования вашей функции в ответ на входящие запросы. Вы можете установить максимальное количество экземпляров для отдельной функции во время развертывания, и каждая функция может иметь свой собственный предел максимального количества экземпляров.
Документация
Compute Engine — виртуальные машины с оптимизированными вычислениями (C2): alpha
В этом выпуске представлено новое семейство экземпляров виртуальных машин, которые оптимизированы для согласованных высокопроизводительных рабочих нагрузок и обеспечивают повышение производительности более чем на 40% по сравнению с текущими виртуальными машинами GCP. Используя масштабируемые процессоры Intel Xeon второго поколения, виртуальные машины C2 могут работать на постоянной тактовой частоте 3,8 ГГц.
Блог
Compute Engine — виртуальные машины с оптимизированной памятью (M2): альфа
Виртуальные машины M2 предлагают самую высокую конфигурацию памяти для виртуальной машины Compute Engine. Они идеально подходят для нагрузок с интенсивным использованием памяти, таких как большие базы данных в памяти и аналитические данные в памяти. Наши новейшие дополнения предлагают до 12 ТБ памяти и 416 виртуальных ЦП.
Блог
Cloud Run: бета
Cloud Run переносит серверы в контейнеры, абстрагируя все управление инфраструктурой, так что вы можете сосредоточиться на создании приложений. Теперь вы можете запускать HTTP-контейнеры без сохранения состояния в полностью управляемой среде или в вашем кластере Kubernetes Engine.
Страница продукта |
Блог
Compute Engine — явная локализация для снимков: GA
Теперь клиенты могут контролировать локальность данных при создании снимков зональных или региональных постоянных дисков. Для хранения снимков клиенты могут выбрать мультирегиональное хранилище облачного хранилища (доступно в США, Европе и Азии) или определенный регион облачного хранилища.
Документация
УПРАВЛЕНИЕ API
Установщик Apigee Edge для Pivotal Cloud Foundry: GA
Этот последний выпуск BOSH упрощает установку, управление и обслуживание Apigee Edge для частного облака 4.19.01. Одной из ключевых новых функций является новый интерфейс Apigee Edge и поддержка спецификации OpenAPI v3.
Документация
ИНСТРУМЕНТЫ УПРАВЛЕНИЯ
Stackdriver Profiler: GA
Этот статистический профилировщик с минимальными накладными расходами позволяет непрерывно собирать информацию об использовании ЦП и распределении памяти из ваших производственных приложений. Вы можете определить характеристики производительности кода, например, какие части потребляют больше всего ресурсов.
Документация
ИНСТРУМЕНТЫ РАЗРАБОТЧИКА
Облачный код
Этот новый набор плагинов для IntelliJ и Visual Studio Code помогает ускорить
Страница услуги.
Блог